Text From Xcode
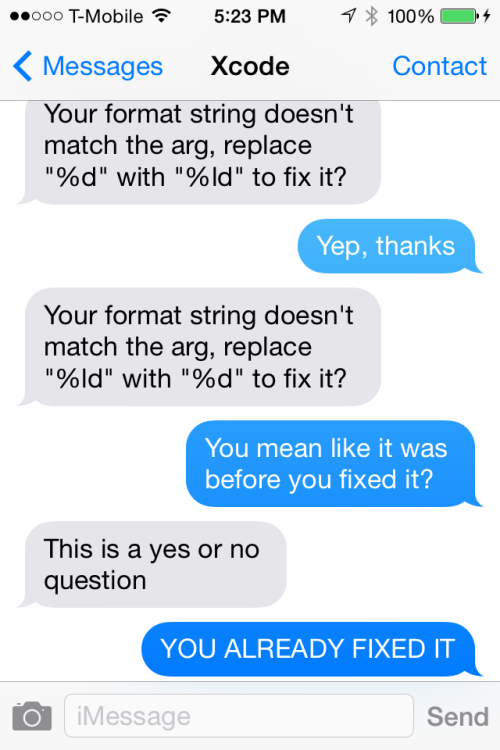
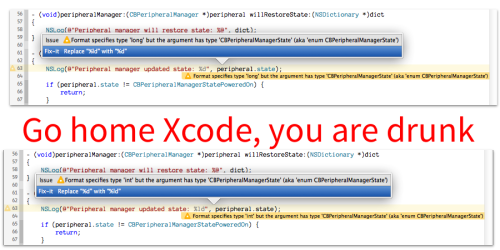
If you've never read Text From Xcode, go. Now.
If you've never read Text From Xcode, go. Now.
The King Makers: Apple Takes Down an Indie Dev | rollinsio:
On September 26, Greg submitted what he believed was a valid compromise: The click would take the user to the main Launcher app, and from there the app would call the appropriate action. Apple rejected the update and within an hour Launcher was no longer on the App Store.
EBay Will Spin Off PayPal Into a Separate Company | WIRED:
EBay is breaking away from PayPal, turning its payments operation into a separate, publicly traded company.
I have four Backup Plus Desktop drives. Two were bought two years ago and two last year.
All of them had an issue where they would drop off the USB bus sometimes and require a power cycle to return. I looked around and found a firmware update that promised a fix. However, it would only apply to two of them (the newer ones). The older ones (which looked identical, of course) didn’t show up in the tool.
Too busy to be bothered, I let this go for a while and just dealt with it.
Recently, however, I decided to RAID them together as a backup device for my server’s RAID. (How do you backup a RAID? With another RAID.) Well, you can imagine how well RAID likes it when a disk randomly falls off the bus.
I looked into this further and found something darkly hilarious (after trying to update the firmware again). Those older drive models that wouldn’t appear in the updater? System Profiler showed them as having a USB identifier of 0xa0a1. The new ones have 0xa0a4. Seagate omitted an entire line of devices from the update tool.
Well, okay, Seagate can eat an RMA then, because a drive falling off the bus is a failure in my head (and my warranty is up in September, so this is my window). I went through the process on their site several times and was rejected every time with an invalid product ID.
SEAGATE DOESN’T KNOW THEY MADE THESE DRIVES.
That’s the only conclusion I can come to. The firmware updater hasn’t heard of them and the warranty system hasn’t heard of them (kind of — the checker gave me the dates just fine, but I couldn’t start an RMA).
In the end, I found that using the part number of the newer drive with the serial of the older worked to get it in the system. Clever, no?
Well, it would have been. Turns out that while that let me send in the RMA, their system appears to know about that model somewhere deeper in the system and when I got my two replacement drives one was the newer a4 ID and the other the older a1 ID. Lovely.
I did have a solution at the ready, though. I have yet another drive of that model that I use as a solo backup drive for my Mac. The USB widget attached to it read as an A4 so I swapped out that part and carried on with the only A1 device being the one that is intermittently connected to my Mac, and where a random long-term drop off wouldn’t be noticed.
Lesson: if you get a Seagate Backup Plus drive, ensure the USB family ID is 0xa0a4 and use the latest firmware. They’re pretty solid devices at that point.
It used to be, back in the days of white-on-black email and newsgroups, that you were able to keep a copy of everything you did on the Internet. Well, mainly it was because you did two or three things and they all required specific client software that had the option of keeping copies of your contributions, but there it was, you could do it. I, for instance, have a majority of my email back to 1996 — that includes mail from Compuserve, AOL, Eudora, Claris Emailer, Outlook Express, and now Apple Mail. My newsgroup client keeps copies of all my sent messages as well, still. That’s another old, large archive.
What I don’t have, really, is a copy of all my comments on the web. Comments on blogs, stores, pictures, videos, links, and others are all on those sites and not something that’s automatically kept around by me. And when I post something material to a site like Flickr or Vimeo, it’s on that server, not mine. I don’t automatically get a copy of it or anything like that.
Practically, this means that my content is so spread out that I’m likely to lose contact with a lot of it, even a majority of it. As someone with more than 10 years of email, that bothers me.
What I want is a way to have places kind of ping back to me what content I’ve made so that I can keep track of it. If there’s a standard way of doing this, then we can all have little personal content services that store everything we’ve made, anywhere, so that we can keep everything we’ve generated.
One solution would be to base it off your email address. Say I’m ted@example.com, for example. When I enter that into a comment field, the remote server would do a SRV DNS query for example.com for some service (say, “archive”) and see who handles it. It would then ask that server (perhaps in some XML-RPC or RESTy way) if it handles the account ted@example.com. If so, it would say: “He posted a comment on my site. Here’s the text of it and a URL for it.” Et voila! I now have a reference to and archive of my comment.
Similarly, media sites would ping back and give URLs to the raw content that was uploaded. Some archive softwares would opt to pull that down and mirror it for safe keeping, while others (presumably larger services) would just keep the URLs around and maybe a thumbnail.
I want this. Badly.
OpenBSD forks, prunes, fixes OpenSSL | ZDNet:
Theo de Raadt, founder and leader of the OpenBSD and OpenSSH, tells ZDNet that the project has already removed 90,000 lines of C code and 150,000 lines of content. de Raadt: “Some of that is indentation, because we are trying to make the code more comprehensible. 99.99% of the community does not care for VMS support, and 98% do not care for Windows support. They care for POSIX support, so that the Unix and Unix derivatives can run. They don’t care for FIPS. Code must be simple. Even after all those changes, the codebase is still API compatible. Our entire ports tree (8700 applications) continue to compile and work, after all these changes.”
The network nightmare that ate my week | Occasionally Coherent:
I used Ubuntu as an example, but it is hardly the worst offender. We have seen Windows machines with more than 300 IPv6 addresses — which, recall, means that every 150 seconds they will be transmitting 30 multicast packets per second which have to be flooded through the network.
After reading a lot about various evil ISPs and other such fun I decided it would be good to have a self-controlled VPN server out there for when I am using a device of mine on a network I'm not so sure about. I could pay someone else for this, sure, but I already have a server "out there" that's not being used to its fullest capabilities and I'm pretty handy with the Linux and the vi so ... why not?
Using a recent Ubuntu, I did the following:
apt-get install pptpd /etc/pptpd.conf: localip 192.168.0.1 remoteip 192.168.0.101-200 /etc/ppp/chap-secrets: [username] * [password] * /etc/ppp/options.pptpd: ms-dns 8.8.8.8 ms-dns 4.4.4.4 /etc/sysctl.conf: net.ipv4.ip_forward = 1 sysctl -p ufw default allow ufw enable ufw allow [things you use, like ssh, http, https, pptp(!), etc.] ufw [and carry on to your heart's content] ufw default deny #BE CAREFUL! service pptpd restart
I'd explain it line-by-line but I'm going on a simple notion here: if you can't understand that, you shouldn't be running a VPN server and more research is needed on your behalf.
I've tested it with both my MacBook Pro and my iPhone and it works like a charm (traceroutes and routing tables confirm usage).
So now if I'm on someone else's network and need to do something that I really don't need snooping on, I have a solution. Now, Rackspace charges $0.12/GB for outbound traffic so I can't leave it on all day, but when I need it I won't be pulling down OS installs, either.
Now you just have to worry about the leg of the Internet from your server to the other server, and that's what SSL is for. This just keeps them from mucking with your data on the last leg (DNS, content injection, port-based throttling (unless they throttle VPN, of course)) and it keeps people in public areas from casually reading your email because you're a moron and using a non-SSL connection anyway.
It's 128-bit encryption and can be busted in a short (hours) timeframe. Don't go believing you're bulletproof -- you're not. You're safer, not safe. You've moved out of the "easy pickings" group and into the "too much effort" group. But if you pull this at DEFCON you'll find yourself the virtual equivalent of drugged, stripped, and handcuffed to a police car at 2am with "I HAZ DONUTS" Sharpied on your forehead.
Context matters.
Why are Mac OS X aliases so large? They're huge! I've seen sizes from 1MB to 5MB for a single alias file. Back in the System 7 days they were mere bytes in size. Their functionality hasn't significantly1 changed since then.
I poked around an alias file (with the help of xattr, DeRez, and GetFileInfo) and found the answer: they're storing icons in there now.
Twice. Once in the data fork of the file and then once in the resource fork of the file.
What? Why? To make it look pretty, of course. Well, to be fair, it's so that the alias retains its appearance if you used a custom icon on the original or if the source application is no longer available. But still, 5MB for a file reference to what could be a 10KB file? Insanity.
So I tapped my memory for what made an old-school alias. It was a simple 'alis' resource back in the day. Sure enough, DeRez said that was still in there. With some trial-and-error at copying all the old-school HFS attributes I managed to find a way to take an existing obese alias and thin out all the stuff that doesn't make it an alias file. Then I made it a script that takes makes a copy of the original with all the crap stripped out2.
The result? A file that goes from 5MB to 700 bytes. Bytes. It still works, even grabbing files in subfolders on network shares. (Well, the 'alis' resource is still there, of course!)
1. Lion introduced "bookmark" data to them which does give them more robustness when the originals move around, but that's about it.
2. It works on a copy of the file because that's the state of the script when I finally got it working. As I have other things to do, that's where I stopped. If you want to replace the original just chain a mv afterwards (./strip_alias.sh alias alias-new; mv alias-new alias). You are free to fork the gist and improve it now that the hard part has been done.
A series of events unfolded recently that led me to reconsider a lot about my digital life. The short story — and there is a long one — is that my home was broken into and my computers were stolen. The thieves also managed to take some accessories and drives but, astonishingly, left my Time Machine drives for the two computers. While it’s bad, it could have been so much worse.
Let’s start with the bad, then. My tax return was on the desktop of the desktop. My social, income, my son’s social, and the 8332 with the ex’s social were all inside a regular PDF file on the desktop. Oh, and my credit reports as I’d just gotten my yearly copies. If they dig around a little they’ll come across lots of proprietary source code (at least that’s on an encrypted disk image with no stored password in the keychain).
Then the worse: the computer was set to automatically login and neither the user nor the partition were encrypted. Further, the keychain was — as is the default — set to automatically unlock on login. So if you turned the computer on, you could log in to anything I used without a barrier.
I won’t mince words here: that was just stupid of me. It’s why I’ve decided to change everything about how I live digitally. Hopefully my lessons will serve as warnings to others.
I have renter’s insurance. Again, I’ll be frank: it wasn’t my idea. My apartment complex requires it (and more are) so I got it. My agent gave me a short talk about the Replacement Coverage option and about how, if I have computers, that’s going to save my bacon someday for the measly addition of $30 to the yearly price.
It saved my bacon.
The computers were old (about five years old) and the depreciation table has computers down for a six year life. What this means is that a computer purchased for $1,000 will lose $166.67 of value every year. Without the additional coverage I would have been handed a check for about one sixth of the original value for the equipment and bid a swell day (which it completely would not have been). With the coverage, however, I’m given that check first and then told to show receipts for replacing the equipment at modern prices and they’ll issue additional checks to cover the difference.
My 2008 iMac, MacBook Pro, and Cinema Display have thus morphed into a MacBook Pro (Retina) and Thunderbolt Display (I have two years to buy the iMac and don’t need it right now, so I’ll wait a little for a refresh). The original MBP was mid-line with some additions and that translated to the top-of-the-line MBP with no additions as far as placement on the scale is concerned. Apple sells no other Apple-branded displays than the Thunderbolt at the moment. They even tossed in a Superdrive since Apple killed the optical in that model (so it would be a feature-for-feature replacement). The experience of using my computer instantly went from The Virgin Suicides to Amelie.
Lesson: Get replacement coverage. It was the one thing I did right.
First and foremost, if the Time Machine drives had been taken I would have been hosed. That was a single point of failure in my backup plan. In fairness, I use Arq to backup essentials like my iPhoto library and my source code, but there’s so much more that was not backed up.
What was covered:
What wasn’t covered:
Time Machine saved me, so it stays around1.
The new plan is that now — in addition to local Time Machine backups — I’m adding 100% offsite coverage on backups.
I looked at Backblaze, CrashPlan, Mozy, and Carbonite and was really not taken by any of their solutions.
I chose Arq again for my principal offsite backup. Arq supports both Amazon S3 and Amazon Glacier and those seem like the perfect solution for storing tons of data like this, so I’ll begin that backup soon (which will take weeks). The large data that will never change goes to Glacier; the day-to-day data goes to S3. I’ll need to clean out and organize my data before I start this, but that’s what this week is all about. I know this solution works, I know there are tools out there to get the data out of the archives without Arq being involved, should it die. I know I can order a copy of my data on a disk from Amazon if I need to and then use those tools to copy the data off, as well.
Well, I had two computers. The plan this year was to sell everything and consolidate to just … a MacBook Pro and a Thunderbolt Display.
(pause for effect)
With that so handily taken care of (ignoring the extremely private data loss and insurance deductible), I merged the two Time Machine backups on MBP and now have 400GB of data to sort through, much of it duplicate or outdated data.
Hazel is a must-have and has saved me a tremendous amount of time in this task so far. I created a folder that Hazel watched and then setup a ton of rules on how I wanted the files put in there sorted and Hazel just did it. It did it so well that I eventually just dumped most of my data in the folder and came back to almost everything sorted how I wanted it. I made a few changes to the rules and I’ll tweak it some more, but now I have a veritable Sorting Hat for files. Some go to the folder that will become the root of the Glacier archive and others will get sent over to Documents (and sorted) and be a part of the S3 archive.
Hazel + Arq = Magic
However, there’s more that Hazel has allowed than just that. Now my Downloads folder is smart. When music, movies, or ePubs are downloaded, they’re added to iTunes. When provisioning profiles are downloaded, they’re added to Xcode. When archives are downloaded they’re unpacked and the original archive is filed away based on the source site. I’ve turned off the “open safe downloads” and watch folder features of most of my applications and just made Hazel rules for those.
Lesson: Back up everything you would horribly miss if you had to be without it for more than a week. Also, Hazel.
I know better. That’s the most painful part of this. I know better than to have left my computer in the state it was in. I just felt that the chances of anything happening to me were slim. Then someone breaks into your apartment while you’re out of town and the rules change.
FileVault 2 has been enabled on the new system and my Time Machine backups are encrypted as well. This is the same technology, fundamentally (Core Storage encrypted partitions), but there are some nuances that should be noted about how the keys are handled. For Time Machine, the decryption password is entered on every mount of the drive (most secure) or stored in the keychain (secure enough, but a single point of failure — your account password). For FileVault 2 the keys are stored on the recovery partition and encrypted with your account password. If you have a weak account password then anyone in possession of your system can brute-force the keys and then decrypt the drive. Use a good password.
Before turning FileVault 2 on, you should read more about FileVault 2 and some of the limitations it imposes (no more remote reboots — you must unlock the system at boot to get at the decryption keys). Also, be aware your Apple ID is a potential security hole as well (unset your Apple ID for all accounts to avoid this). Note that the filesystem and mechanism have been researched, are well-documented, and tools are available to mount FileVault 2 disks so your password is all that protects your data.
I bought in to 1Password. Having keychains on different machines that may or may not have had the password I needed, having multiple browsers with their own schemes to store passwords, and then having mobile devices with their own stores of passwords posed several problems.
First, I don’t know how well any of them are really keeping my passwords secure. Keychain is good, but Chrome and Firefox can sync your passwords between machines and how well is it handling that? File security, transport security, server and network security are all important here.
I could research them all and answer those questions but that doesn’t solve the problem of consistency. 1Password does.
I found some scripts to export the Keychain and browser password stores and import them into 1Password. I then cleared out the browser and keychain passwords for anything in 1Password and went on my merry way, syncing over Dropbox and life is good.
Yes, it’s annoying, but do it. As I reset all my passwords (all of them) I turned on two-factor authentication wherever I could. Thankfully, most places that do it have moved to using a standardized method called Time-based One-time Password Algorithm and both the Google Authenticator and Authy apps on the iPhone support snapping a QR-code and hooking in. Authy looks nicer.
I didn’t recover my computers. In all honesty, no thief is going to respond to a reward-bait message on a login screen, but I didn’t even have that. I had Find My Mac installed but made a critical error in using it. I locked it first.
Don’t do that.
You have two options here. You can hope for recovery or you can protect your data. If you hope for recovery then tell FMM to send you the location when it appears again and do nothing else until you get that email. Then tell the police (you filed a report, right?).
If you want to protect your data, tell it to wipe the machine. If you have FileVault 2 enabled it’s as easy as forgetting the encryption keys to the disk and is done in under a second. For other disks, blowing away the filesystem is a good start, but I’m not sure how it proceeds after that.
Why these two methods? If the thief knows you have a remote in to the machine, he’s going to just disconnect it from the network and brute-force his way in, if that’s what he wants. If you show your hand, you’ve lost the machine. If you’re willing to write the machine off, then just trash the data.
Locking the machine is useful in exactly one case: you have a reward message on the login screen and you’ve lost the machine, not had it stolen.
So, here I am with a nice new setup, my data back, and my personal life exposed to someone out there who I hope cares so little that he’s wiped the machine already. Bittersweet, but I’ve learned a few lessons.
1 One thing to note about Time Machine in general is that it has a tight tie-in with Spotlight. Even if you drag the disk to the Privacy area of the Spotlight preferences, the distinct Spotlight store in the Backups folder will still exist and stay active. Why is this a problem? About 15 years’ of emails takes a while to index. Even though the drives could work faster, Spotlight doesn’t. I got about 5MB/s as it chugged through the Mail folder (opensnoop on backupd was essential here).